



















背景
传统的IT运维中,人工监控和分析关键性能指标(KPI)是预测系统行为和资源利用的常见做法。然而,这种方法耗时、易出错且无法跟上现代IT系统的复杂性和规模。 随着数字化、物联网和人工智能的发展,时序数据的体量和速度增加了指数倍,使得利用高级算法来提取见解和驱动自动化变得至关重要。 时序预测是智能运维的一个关键组件,能够实现资源规划、容量优化和异常检测。通过分析历史数据,时序预测算法可以预测未来系统行为、资源利用和潜在瓶颈,从而使IT团队能够采取预防措施,确保系统的可靠性、性能和效率。 1、资源容量规划:准确的预测资源利用使IT团队能够有效地规划和分配资源,减少浪费,确保系统的最佳性能。 2、自动扩缩:通过预测资源利用,时序预测算法可以触发自动扩缩资源,确保系统能够处理突然的需求激增。 3、预防维护:预测算法可以识别潜在的系统故障,使IT团队能够计划维护,减少停机时间。
LDM时序预测算法结构
LDM(Logsparse-Decomposable-MultiScaling)模型是一种用于时间序列预测的深度学习模型,在处理长时间序列数据拥有优秀的鲁棒性,通过多尺度分解和层次化特征提取来提高预测性能。下图是该算法模型的结构图。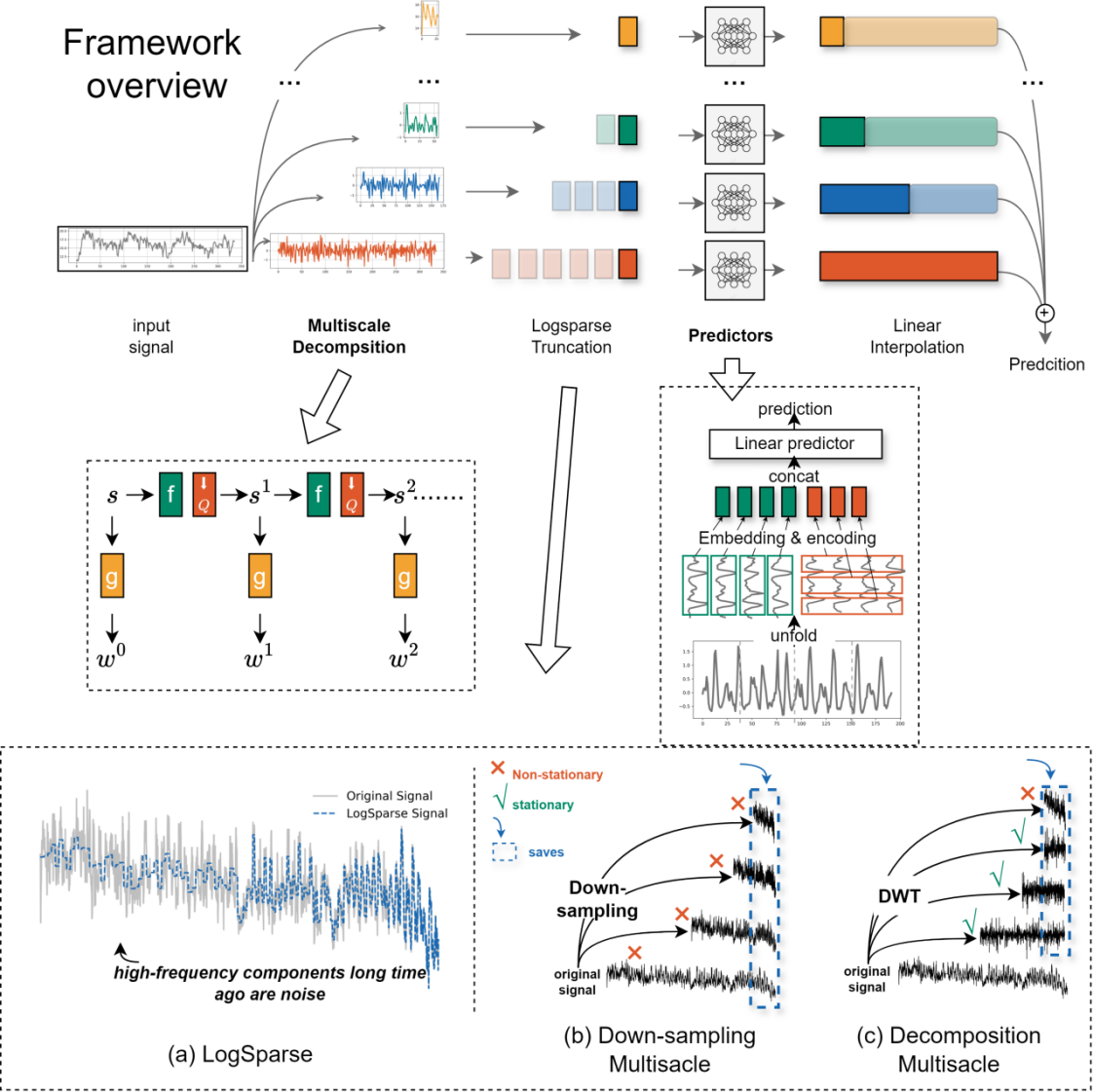
LDM算法将时间序列预测模型分为三个核心部分:稀疏注意力机制、时间序列分解和多尺度建模。 稀疏注意力机制--Logsparse
● 稀疏注意力机制: Logsparse通过稀疏化注意力机制来提升计算效率,尤其是在处理长时间序列时。稀疏注意力通过仅关注序列中的一部分信息来减少计算量,与全注意力机制相比,能够在保持模型性能的同时大幅降低计算复杂度。
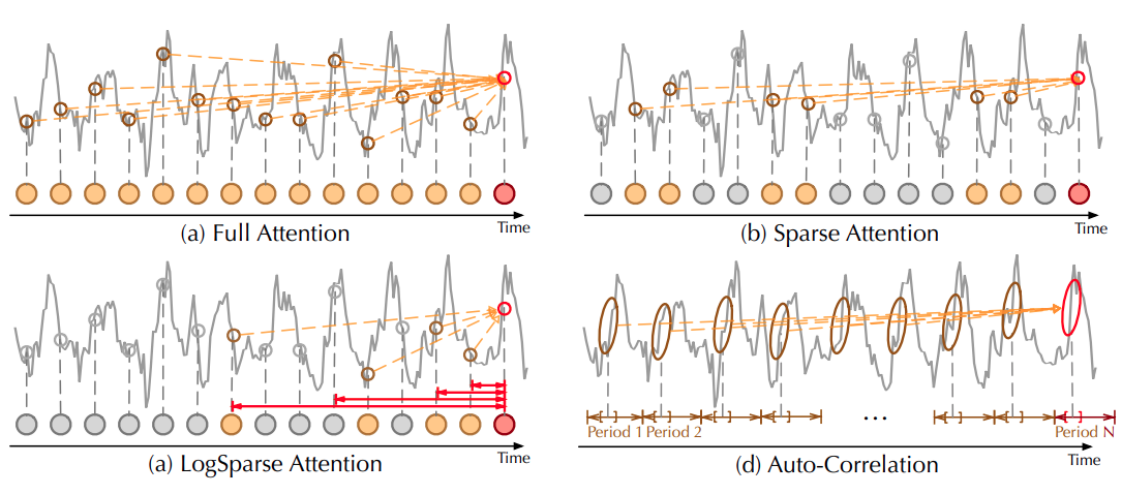
自注意力分数揭示了序列内部元素之间的相关性,这是理解和处理序列数据时至关重要的信息。 然而,值得注意的是,自注意力分数往往呈现出长尾分布的特征,其中大部分的注意力权重集中在少数几个关键的元素上,而其他大部分元素的注意力权重则相对较小。 这表明,在序列中只有少数的元素对当前的预测或决策具有显著的作用。因此,可以将原始自注意力机制进行稀疏化。 LogTrans模型提出了对数稀疏自注意力机制,让每个点只关注前一个具有指数步长的点,也就是只选择具有指数步长的点参与点积运算,从而将计算复杂度降低到了o(LlogL)。 1、对数步长选择: a. 对于序列中的每个位置i,计算其注意力时,只考虑与位置i、i-1、i-2、i-4、i-8、...等位置的交互。 b. 这种选择方式类似于二进制系统中的按位选择,能够在保持重要信息的同时减少不必要的计算。 2、稀疏矩阵构建: a. 通过上述选择策略,构建一个稀疏的注意力矩阵,其中仅在选定的位置对之间进行点积运算。 b. 这种稀疏矩阵显著减少了计算量,使得整体复杂度降低到o(LlogL)𝑂,其中𝑂是序列长度。 3、长尾分布的利用: a. 自注意力分数的长尾分布特性表明,大多数注意力权重集中在少数关键元素上。 b. LogSparse机制通过稀疏化,专注于这些关键元素,从而提高模型的效率和性能。 ● 提高效率: 在长时间序列中,计算全注意力机制的复杂度是平方级的,而稀疏化技术可以将其降低到线性级别,使得处理长序列成为可能。 ● 捕捉长程依赖: 在长时间序列中,重要的信息可能分布在序列的不同部分,稀疏注意力机制能够有效地捕捉这些长程依赖关系。 时间序列分解--Decomposable
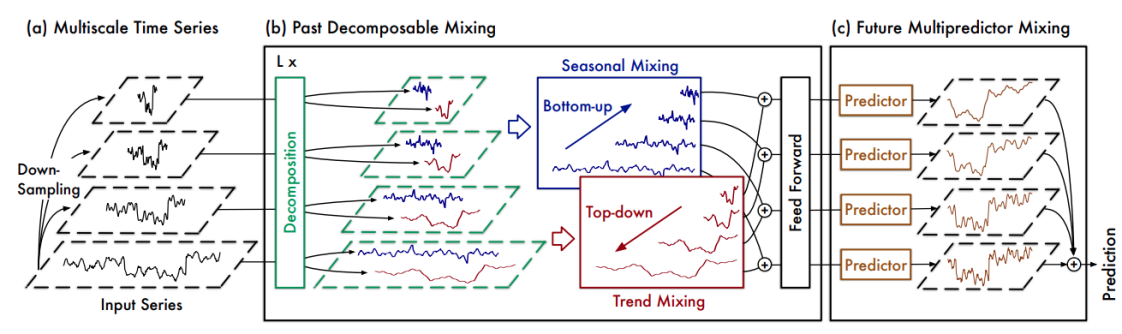
时间序列分解: 这一部分利用技术将时间序列分解为不同的成分,如趋势、季节性和残差。TimeMixer模型中提出Multiscale Time Series、Past Decomposable Mixing、Future Multipredictor Mixing技术,简单解释为: ● Multiscale Time Series:首先对输入序列进行不同程序的池化层来下采样得到不同尺度的序列。 ● Past Decomposable Mixing:然后将每个尺度的序列都分解为趋势项(trend)和周期项(seasonal)(这里分解方法采用的是Autoformer中的方式,用一个大window size的滑动平均即可)。为了进行尺度间的交互,将每个尺度序列的seasonal项按照从下到上(bottom-up)的方式进行信息融合,将每个尺度序列的trend项按照从上到下(top-down)的方式进行信息融合。这里不同尺度之间信息融合的方式就是直接用MLP在时间上对齐到相同的尺度然后相加。 多尺度建模--MultiScaling
● Future Multipredictor Mixing:将Past Decomposable Mixing每一个block输出的不同尺度的序列都用来预测,把所有尺度的预测结果加起来得到最终预测结果。主要用途: ● 捕捉多重时间模式: 不同的时间尺度可能对应于不同的周期性或趋势性特征,多尺度建模能够捕捉这些特征。 ● 增强模型的泛化能力: 通过在多个尺度上进行建模,模型能够更好地适应不同类型的时间序列数据。 ● 提高对长短期依赖的建模能力: 在长时间序列中,不同的时间尺度可能反映了不同的依赖关系,多尺度建模能够同时捕捉长短期依赖。 总结
下图是LDM算法在实际采集数据集下的时间序列预测表现,在长时序列输入下分别预测96、192、336、720个时间节点的数据。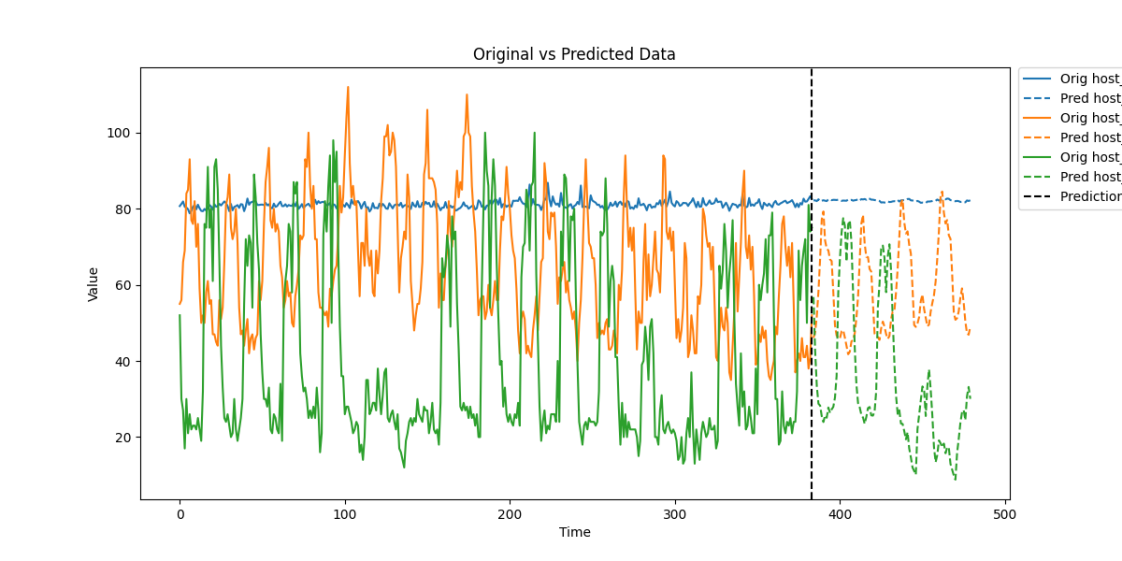
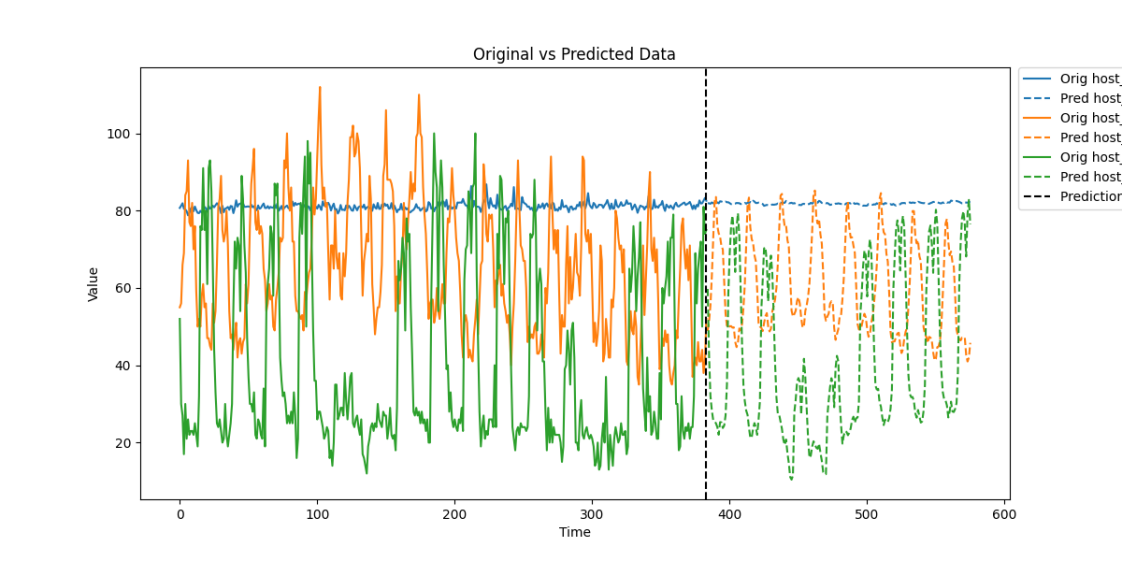
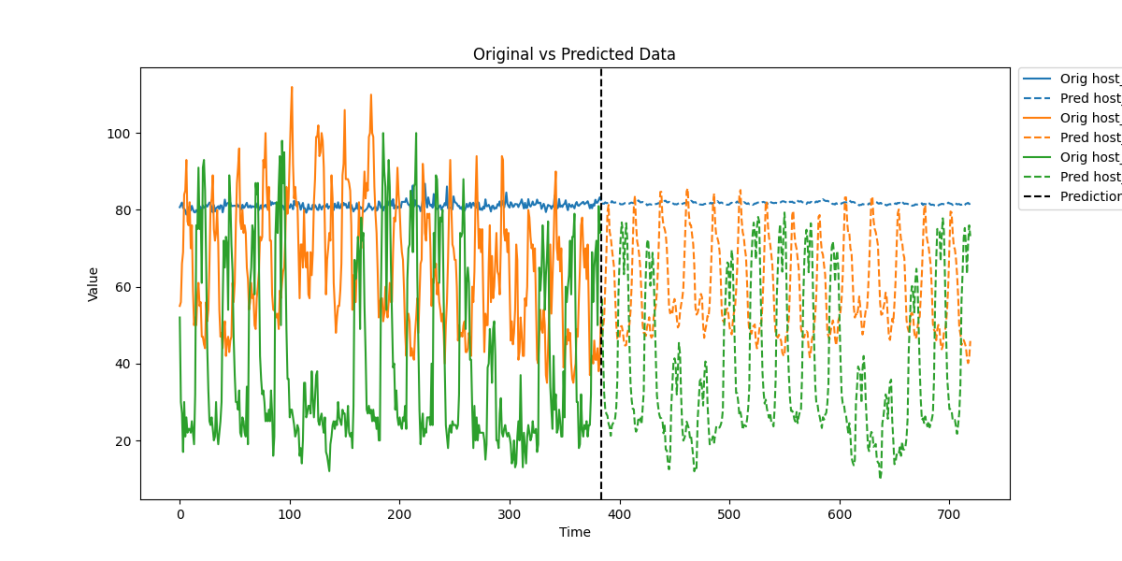
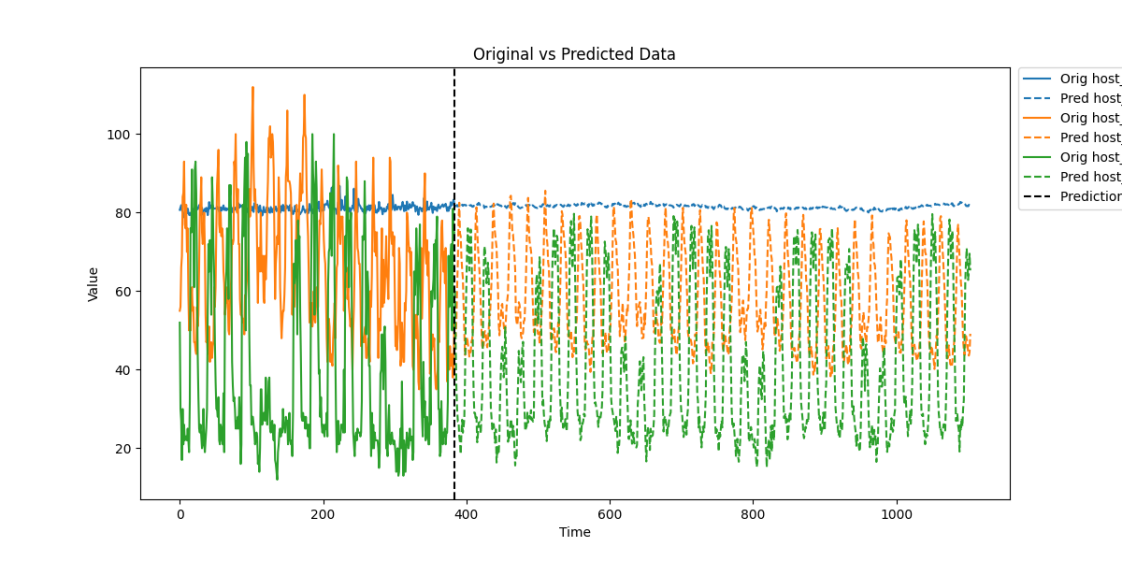
通过引入LDM算法,蒙帕在智能运维领域显著提升了时间序列预测的效率与准确性。该算法结合Logsparse稀疏建模、可分解结构和多尺度分析,能够有效处理包含周期性和非平稳性特征的复杂KPI数据,克服长序列数据的计算效率瓶颈,同时精准捕捉复杂的时间模式,提高预测的准确性和模型的可解释性。 在资源容量规划方面,蒙帕利用LDM算法精准预测系统资源的使用趋势,帮助运维团队提前规划资源分配,避免资源瓶颈,确保系统的高效运行。此外,基于LDM算法的预测结果,蒙帕的解决方案支持自动扩缩容和预防性维护,通过动态调整资源配置和提供数据支持,降低系统故障风险,减少停机时间,确保无缝的服务交付。 蒙帕始终致力于通过技术创新和专业服务,为客户提供高效精准的智能运维解决方案。LDM算法的应用不仅提升了蒙帕在智能运维领域的技术实力,也为客户在数字化转型中提供了强有力的支持,为企业实现资源优化配置和业务连续性提供坚实保障。


电话: 400-166-0296
邮箱: contact@moonpac.com
地址: 上海市闵行区申长路990弄
虹桥汇 T6-805